
elevne's Study Note
딥러닝 파이토치 교과서 (5: 설명가능한 CNN) 본문
설명가능한 CNN, Explainable CNN 은 딥러닝 처리 결과를 사람이 이해할 수 있는 방식으로 제시하는 기술이다. 이는 CNN 을 구성하는 각 중간계층부터 최종분류까지 입력된 이미지에서 특성이 어떻게 추출되고 학습하는지를 설명할 수 있다. CNN 의 시각화 방법에는 필터에 대한 시각화와 특성맵에 대한 시각화가 있는데 서적에서는 특성맵의 시각화만 다루고 있다.
Feature Map 은 입력 이미지 또는 다른 특성 맵처럼 필터를 입력에 적용한 결과이다. 특정 입력 이미지에 대한 특성 맵을 시각화한다는 의미는 특성 맵에서 입력 특성을 감지하는 방법을 이해할 수 있도록 돕는 것이다. 우선 필요한 라이브러리들을 import 해준다.
import matplotlib.pyplot as plt
from PIL import Image
import cv2
import torch
import torch.nn.functional as F
import torch.nn as nn
from torchvision.transforms import ToTensor
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
그 후 아래와 같은 모델을 정의해준다.
class XAI(torch.nn.Module):
def __init__(self, num_classes=2):
super(XAI, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Conv2d(64, 64, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(128, 128, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(256, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(256, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 512, bias=False),
nn.Dropout(0.5),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(-1, 512)
x = self.classifier(x)
return F.log_softmax(x)
forward 함수 내에서는 F.log_softmax 가 사용되었다. 로그 소프트맥스는 신경망 말단의 결괏값들을 확률 개념으로 해석하기 위해 소프트맥스 함수의 결과에 log 값을 취한 연산이라고 한다. Softmax 를 사용하지 않고 Log Softmax 를 사용하는 이유는 Softmax 가 기울기 소멸 문제에 취약하기 때문이라고 한다.
model=XAI()
model.to(device)
model.eval()
model.eval() 메서드를 통해서 모델의 구조를 출력하여 확인해볼 수 있다. 이 모델에서 특성 맵의 결과를 확인하기 위해서 함수를 하나 또 새로 정의해야 한다. 특성 맵은 합성곱층을 입력 이미지와 필터를 연산하여 얻은 결과이다. 따라서, 합성곱층에서 입력과 출력을 알 수 있다면 특성맵에 대한 값들을 확인할 수 있다.
class LayerActivations:
features=[]
def __init__(self, model, layer_num):
self.hook = model[layer_num].register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
output = output
self.features = output.to(device).detach().numpy()
def remove(self):
self.hook.remove()
__init__ 에서 hook 기능을 사용하는 것을 확인할 수 있다. Pytorch 에서는 매 계층마다 print 문을 사용하지 않더라도 hook 기능을 사용하여 각 계층의 활성화 함수 및 기울기 값을 확인할 수 있게끔 한다. register_forward_hook 의 목적은 순전파 중 각 네트워크 모듈의 입력 및 출력을 가져오는 것이다.
이제 특성맵을 추출해볼 이미지를 한 번 시각화해본다.
img=cv2.imread("/content/drive/MyDrive/Colab Notebooks/딥러닝파이토치/data/catanddog/test/Dog/8100.jpg")
plt.imshow(img)
img = cv2.resize(img, (100, 100), interpolation=cv2.INTER_LINEAR)
img = ToTensor()(img).unsqueeze(0)
print(img.shape)

cv2.resize 는 이미지의 크기를 변경할 때 사용되는데, 3 개의 파라미터를 받는다. 첫 번째로는 변경할 이미지 파일, 두 번째로는 변경될 이미지 크기(너비, 높이), 마지막으로는 보간법을 받는다. 이러한 방식으로 이미지의 크기를 변형할 경우에는 변형된 이미지의 픽셀을 추정해서 값을 할당해야 한다. 이미지 비율을 변경하면 존재하지 않는 영역에 새로운 픽셀 값을 매핑하거나 존재하는 픽셀들을 압축해서 새로운 값을 할당하게 되는 것인데, 이러한 상황을 피하고자 이미지 상에 존재하는 픽셀 데이터들에 대해 근사 함수를 적용해서 새로운 픽셀 값을 구하는 것이 보간법이다.
또, 위에서 사용된 unsqueeze() 메서드는 1 차원 데이터를 생성하는 함수이다. 이미지 데이터를 텐서로 변환하고 그 변환된 데이터를 1 차원으로 변경한다는 의미인 것이다.
result = LayerActivations(model.features, 0)
model(img)
activations = result.features
model 에 이미지를 넣고 그 특성맵을 activation 안에 담는 코드이다. 이를 아래와 같이 시각화해볼 수 있다.
fig, axes = plt.subplots(4,4)
fig = plt.figure(figsize=(12, 8))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for row in range(4):
for column in range(4):
axis = axes[row][column]
axis.get_xaxis().set_ticks([])
axis.get_yaxis().set_ticks([])
axis.imshow(activations[0][row*10+column])
plt.show()

위 그림은 첫 번째 Conv2d 게층에서의 특성맵에 대한 출력 결과인 것이다. 입력층과 가깝기에 입력 이미지의 형태가 많이 유지되고 있는 것을 확인할 수 있다. 조금 더 깊은 30 층을 한 번 확인해본다.
result = LayerActivations(model.features, 30)
model(img)
activations = result.features
fig, axes = plt.subplots(4,4)
fig = plt.figure(figsize=(12, 8))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for row in range(4):
for column in range(4):
axis = axes[row][column]
axis.get_xaxis().set_ticks([])
axis.get_yaxis().set_ticks([])
axis.imshow(activations[0][row*10+column])
plt.show()
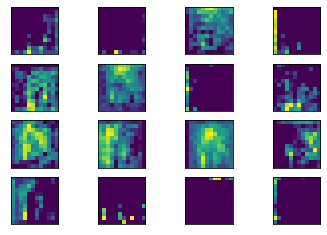
더 이상 기존 개의 형태를 찾아볼 수 없게 되었다.
이와 같은 코드들로 CNN 의 내부 구조를 살펴볼 수 있는 것이다.
Reference:
딥러닝 파이토치 교과서

'Machine Learning > Pytorch' 카테고리의 다른 글
| 딥러닝 파이토치 교과서 (6-2: AlexNet) (0) | 2023.03.16 |
|---|---|
| 딥러닝 파이토치 교과서 (6-1: LeNet) (1) | 2023.03.15 |
| 딥러닝 파이토치 교과서 (4-2: CNN 전이학습(3)) (0) | 2023.03.13 |
| 딥러닝 파이토치 교과서 (4-2: CNN 전이학습(2)) (0) | 2023.03.12 |
| 딥러닝 파이토치 교과서 (4-2: CNN 전이학습) (0) | 2023.03.11 |



