
elevne's Study Note
Java - Multi Thread (4) 본문
병렬 작업 처리가 많아지면 스레드 개수가 증가되고, 그에 따른 스레드 생성과 스케줄링으로 인해 CPU 가 바빠져 메모리 사용량이 늘어난다. 갑작스런 병렬 작업의 폭증으로 인한 스레드의 폭증을 막기 위해 ThreadPool 을 사용할 수 있다고 한다. 이는 작업처리에 사용되는 스레드를 제한된 개수만큼 정해두고 작업 Queue 에 들어오는 작업들을 하나씩 스레드가 맡아서 처리하는 것이다. Java 는 스레드풀을 생성하고 사용할 수 있도록 java.util.concurrent 패키지에서 ExecutorService 인터페이스와 Executors 클래스를 제공한다.
ExecutorService executorService = Executors.newCachedThreadPool();
ExecutorService executorService1 = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
ExecutorService executorService2 = new ThreadPoolExecutor(3, 100, 120L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
newCachedThreadPool() 메서드로 생성된 스레드풀의 초기 스레드 개수와 코어 스레드 개수는 0 개이며 (코어 스레드 수는 스레드 수가 증가된 이후 스레드풀에서 최소한 유지해야 할 스레드 수) , 스레드 개수보다 작업 개수가 많으면 새 스레드를 생성시켜 작업을 처리한다. 이 때, 한 개 이상의 스레드가 추가되었을 경우 60 초 동안 추가된 스레드가 아무 작업을 하지 않으면 추가된 스레드를 종료하고 풀에서 제거한다.
newFixedThreadPool(int nThreads) 메서드로 생성된 스레드풀의 초기 스레드 개수는 0 으로 동일하지만, 코어 스레드 수는 인자로 받는 nThreads 이다. 마찬가지로 스레드 개수보다 작업 개수가 많으면 새 스레드를 생성시키고 처리하지만, 최대 스레드 개수는 newCachedThreadPool() 과 다르게 nThreads 이다. (위 코드를 사용하면 CPU 코어의 수만큼 최대 스레드를 사용하는 스레드 풀을 생성한다)
또, ThreadPoolExecutor 객체를 직접 사용할 수 있다. (위 두 메서드 또한 ThreadPoolExecutor 을 내부적으로 생성해서 리턴하는 것) 위 코드는 코어 스레드 개수는 3 개, 최대 스레드 개수는 100 개, 코어 스레드 3 개를 제외한 나머지 추가된 스레드가 120 초 동안 아무것도 하지 않을 경우 해당 스레드를 제거하는 스레드 풀을 생성한다. (new SynchronousQueue<Runnable>() 은 작업 큐)
스레드풀의 스레드는 데몬 스레드가 아니기에, main 스레드가 종료되어도 작업을 처리하기 위해 계속 실행상태로 남아있게 된다. 애플리케이션을 종료하려면 스레드풀 또한 종료시켜 스레드들이 종료상태가 되도록 처리해줘야 한다. shutdown() 메서드를 사용하여 현재 처리 중인 작업과 작업 큐에 대기하고 있는 모든 작업을 처리한 뒤 스레드 풀을 종료시킬 수 있고, shotdownNow 를 사용하여 바로 종료시킬 수도 있다. (그 외에 awaitTermination; shotdown() 메서드 호출 이후 모든 작업 처리를 일정 시간 내에 완료하면 true, 아니면 false 를 반환하는 메서드를 사용할 수 있다)
작업을 생성할 때는 Runnable 또는 Callable 구현 클래스를 사용한다.
Runnable task = new Runnable() {
@Override
public void run() {
// 스레드가 처리할 내용
}
};
Callable<String> task2 = new Callable<String>() {
@Override
public String call() throws Exception {
// 스레드가 처리할 내용
return null;
}
};
위와 같은 형식의 구현클래스들을 이용하여 작업 처리 요청을 할 수 있다. 이 때 execute 혹은 submit 메서드가 사용된다. execute() 는 작업 처리 결과를 받지 못하고, submit() 은 작업 처리 결과를 받을 수 있도록 Future 객체를 리턴한다. 또 다른 차이점으로, execute() 는 작업 처리 중 예외가 발생되면 스레드가 종료되고 해당 스레드는 스레드풀에서 제거되지만 submit() 은 예외가 발생하더라도 스레드는 종료되지 않고 다음 작업을 위해 재사용된다. (그렇기 때문에 가급적이면 스레드의 생성 오버헤더를 줄이기 위해 submit() 을 사용하는 것이 좋다고 한다)
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(2);
for (int i=0; i<10; i++){
Runnable task = new Runnable() {
@Override
public void run() {
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executorService;
int poolSize = threadPoolExecutor.getPoolSize();
String threadName = Thread.currentThread().getName();
System.out.println("총 스레드 개수: "+poolSize+" / 작업스레드 이름: "+threadName);
int value = Integer.parseInt("삼");
}
};
executorService.submit(task);
Thread.sleep(500);
}
executorService.shutdown();
}

위 결과를 보면 계속 Runnable 구현클래스가 run() 메서드 내에서 예외를 발생시키지만, thread-1, 2 를 삭제시키지 않고 계속 재사용하는 것을 확인할 수 있다. ( submit() 메서드의 특징 )
위에서 사용된 submit() 메서드는, 매개값으로 준 Runnable 또는 Callable 작업을 스레드 풀의 작업 큐에 저장하고 즉시 Future 객체를 리턴한다. Future 객체는 작업 결과가 아니라 적업이 완료될 때까지 기다렸다가 (블로킹) 최종 결과를 얻는데 사용되는 것이다. ( Future 객체를 Pending Completion (지연완료) 객체라고도 한다 ) get() 메서드를 호출하여 스레드가 작업을 완료할 때까지 블로킹되었다가 작업을 완료하면 처리 결과를 얻어낼 수 있다. 이 때 주의할 점으로, 작업을 처리하는 스레드가 작업을 완료하기 전까지는 get() 메서드가 블로킹되므로 다른 코드를 실행할 수 없다는 것이다. (그렇기 때문에 get() 메서드를 호출하는 스레드는 새로운 스레드이거나 스레드풀의 또다른 스레드가 되어야 한다고 한다)
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
System.out.println("작업 처리 요청");
Callable<Integer> task = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i=1; i<=10; i++) {sum+=i;}
return sum;
}
};
Future<Integer> future = executorService.submit(task);
try {
int sum = future.get();
System.out.println("처리결과: "+sum);
System.out.println("작업 처리 완료");
} catch (Exception e) {
e.printStackTrace();
}
executorService.shutdown();
}
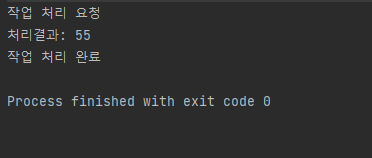
위와 같이 리턴 값이 있을 때는 Callable 구현 클래스를 사용한다. (없을 때는 Runnable)
상황에 따라서 스레드가 작업할 결과를 외부 객체에 저장해야 할 수도 있다. 이 때는 ExecutorService 의 submit(Runnable task, V result) 메서드를 사용할 수 있다. 여기서 V 는 Result 타입으로 메서드를 호출하면 즉시 Future<V> 가 리턴된다. 또, 작업 객체는 여기서 Runnable 구현 클래스로 상성되며 스레드에서 결과를 저장하기 위해 외부 Result 객체를 사용해야 하므로 생성자를 통해 Result 객체를 주입받아야 한다.
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
class Result {
int accumValue;
synchronized void addValue(int value) {
accumValue += value;
}
}
class Task implements Runnable {
Result result;
Task(Result result) { this.result = result; }
@Override
public void run() {
int sum = 0;
for (int i=1; i<=10; i++) {sum+=i;}
result.addValue(sum);
}
}
Result result = new Result();
Runnable task1 = new Task(result);
Runnable task2 = new Task(result);
Future<Result> future1 = executorService.submit(task1, result);
Future<Result> future2 = executorService.submit(task2, result);
try {
result = future1.get();
result = future2.get();
System.out.println(result.accumValue);
} catch (Exception e) {
e.printStackTrace();
}
executorService.shutdown();
}

이 외에도, 스레드풀에서 작업 처리가 완료된 것만 통보받을 수 있는 방법이 있다. CompletionService 를 이용하여 처리 완료된 작업을 가져오는 poll(), take() 메서드를 사용한다. poll() 은 완료된 작업의 Future 객체를 가져오고 없으면 null 을 반환하는 반면, take() 는 완료된 작업의 Future 객체를 가져오고 없으면 있을 때까지 블로킹된다. CompletionService 의 구현클래스는 ExecutorCompletionService<V> 이다. (객체 생성 시 매개값으로 ExecutorService 를 넣으면 된다)
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
CompletionService<Integer> completionService = new ExecutorCompletionService<Integer>(executorService);
for (int i=0; i<3; i++){
completionService.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i=1; i<=10; i++) {
sum += i;
}
return sum;
}
});
}
executorService.submit(new Runnable() {
@Override
public void run() {
while (true) {
try {
Future<Integer> future = completionService.take();
int value = future.get();
System.out.println(value);
} catch (Exception e) {
break;
}
}
}
});
try {
Thread.sleep(3000);
} catch (InterruptedException e) {}
executorService.shutdownNow();
}

마지막으로 Callback 활용법에 대해 알아보았다. 콜백은 어플리케이션이 스레드에게 작업처리를 요청한 후 스레드가 작업을 완료하면 특정 메서드를 자동으로 실행하는 기법을 말한다.

Blocking 방식은 작업 처리를 요청한 후 작업이 완료될 때까지 블로킹되지만, 콜백 방식은 작업 처리를 요청한 후 결과를 기다릴 필요 없이 다른 기능을 수행할 수 있다. 작업 처리가 완료되면 자동적으로 콜백 메서드가 실행되어 결과를 알 수 있다.
ExecutorService 는 콜백 기능을 따로 제공하지 않지만, Runnable 구현 클래스 내에서 이를 구현할 수 있다. 이 때 CompletionHandler 클래스를 사용할 수 있다. CompletionHandler 은 completed() 와 failed() 메서드를 갖고있는데 각각 정상 처리 완료했을 때, 작업 처리 중 예외가 발생했을 때 호출하는 콜백 메서드이다.
public static void main(String[] args) {
class CallbackExample {
private ExecutorService executorService;
public CallbackExample() {
executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
}
private CompletionHandler<Integer, Void> callback = new CompletionHandler<Integer, Void>() {
@Override
public void completed(Integer result, Void attachment) {
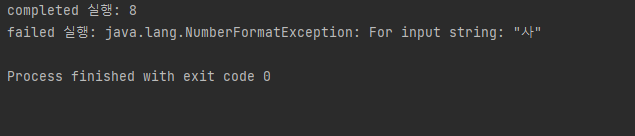
System.out.println("completed 실행: "+result);
}
@Override
public void failed(Throwable exc, Void attachment) {
System.out.println("failed 실행: "+exc.toString());
}
};
public void doWork(final String x, final String y) {
Runnable task = new Runnable() {
@Override
public void run() {
try {
int intX = Integer.parseInt(x);
int intY = Integer.parseInt(y);
int result = intX + intY;
callback.completed(result, null);
} catch (NumberFormatException e) {
callback.failed(e, null);
}
}
};
executorService.submit(task);
}
public void finish() {
executorService.shutdown();
}
}
Reference:
이것이 자바다
https://velog.io/@hanlyang0522/Blocking-vs-Non-Blocking-Sync-vs-Async
'Backend > Java' 카테고리의 다른 글
| Java - Stream (0) | 2023.05.19 |
|---|---|
| Java - Collection (0) | 2023.05.17 |
| Java - Multi Thread (3) (0) | 2023.05.13 |
| Java - Map Compute, To JSON (0) | 2023.05.10 |
| Java - Multi Thread (2) (0) | 2023.05.09 |


