
elevne's Study Note
MySQL 3: Stored Procedure, Function 본문
Stored Procedure 이란 MySQL 에서 제공되는 프로그래밍 기능이며, 쿼리문의 집합으로 어떠한 동작을 일괄처리하기 위한 용도로 사용된다. 아래는 Stored Procedure 을 생성하는 간단한 형식이다.
CREATE PROCEDURE 프로시저이름(
IN 또는 OUT 파라미터
)
BEGIN
--- SQL 프로그래밍 코드 ---
END
위 형식에 맞추어 생성한 프로시저는 CALL 프로시저이름() 으로 호출할 수 있다. 프로시저를 삭제할 때에는 DROP PROCEDURE 을 사용하면 된다.
Stored Procedure 은 실행 시에 입력 매개변수를 지정할 수 있다. 입력된 매개변수는 Stored Procedure 내부에서 다양한 용도로 사용될 수 있다. 입력 매개변수를 지정할 때는 아래와 같이 작성한다.
IN 입력매개변수이름 데이터타입
출력 매개변수를 사용할 때는 위에서 IN 만 OUT 으로 바꿔주면 된다.
실습을 위해 아래 링크에서 예제 데이터를 불러왔다. (해당 링크에서 가져온 예제 데이터 삽입 SQL 문이다)
링크: https://cafe.naver.com/thisisMySQL
이것이MySQL이다 : 네이버 카페
한빛미디어 [이것이 MySQL이다] 카페입니다.
cafe.naver.com
DROP DATABASE IF EXISTS sqldb; -- 만약 sqldb가 존재하면 우선 삭제한다.
CREATE DATABASE sqldb;
USE sqldb;
CREATE TABLE usertbl -- 회원 테이블
( userID CHAR(8) NOT NULL PRIMARY KEY, -- 사용자 아이디(PK)
name VARCHAR(10) NOT NULL, -- 이름
birthYear INT NOT NULL, -- 출생년도
addr CHAR(2) NOT NULL, -- 지역(경기,서울,경남 식으로 2글자만입력)
mobile1 CHAR(3), -- 휴대폰의 국번(011, 016, 017, 018, 019, 010 등)
mobile2 CHAR(8), -- 휴대폰의 나머지 전화번호(하이픈제외)
height SMALLINT, -- 키
mDate DATE -- 회원 가입일
);
CREATE TABLE buytbl -- 회원 구매 테이블(Buy Table의 약자)
( num INT AUTO_INCREMENT NOT NULL PRIMARY KEY, -- 순번(PK)
userID CHAR(8) NOT NULL, -- 아이디(FK)
prodName CHAR(6) NOT NULL, -- 물품명
groupName CHAR(4) , -- 분류
price INT NOT NULL, -- 단가
amount SMALLINT NOT NULL, -- 수량
FOREIGN KEY (userID) REFERENCES usertbl(userID)
);
INSERT INTO usertbl VALUES('LSG', '이승기', 1987, '서울', '011', '1111111', 182, '2008-8-8');
INSERT INTO usertbl VALUES('KBS', '김범수', 1979, '경남', '011', '2222222', 173, '2012-4-4');
INSERT INTO usertbl VALUES('KKH', '김경호', 1971, '전남', '019', '3333333', 177, '2007-7-7');
INSERT INTO usertbl VALUES('JYP', '조용필', 1950, '경기', '011', '4444444', 166, '2009-4-4');
INSERT INTO usertbl VALUES('SSK', '성시경', 1979, '서울', NULL , NULL , 186, '2013-12-12');
INSERT INTO usertbl VALUES('LJB', '임재범', 1963, '서울', '016', '6666666', 182, '2009-9-9');
INSERT INTO usertbl VALUES('YJS', '윤종신', 1969, '경남', NULL , NULL , 170, '2005-5-5');
INSERT INTO usertbl VALUES('EJW', '은지원', 1972, '경북', '011', '8888888', 174, '2014-3-3');
INSERT INTO usertbl VALUES('JKW', '조관우', 1965, '경기', '018', '9999999', 172, '2010-10-10');
INSERT INTO usertbl VALUES('BBK', '바비킴', 1973, '서울', '010', '0000000', 176, '2013-5-5');
INSERT INTO buytbl VALUES(NULL, 'KBS', '운동화', NULL , 30, 2);
INSERT INTO buytbl VALUES(NULL, 'KBS', '노트북', '전자', 1000, 1);
INSERT INTO buytbl VALUES(NULL, 'JYP', '모니터', '전자', 200, 1);
INSERT INTO buytbl VALUES(NULL, 'BBK', '모니터', '전자', 200, 5);
INSERT INTO buytbl VALUES(NULL, 'KBS', '청바지', '의류', 50, 3);
INSERT INTO buytbl VALUES(NULL, 'BBK', '메모리', '전자', 80, 10);
INSERT INTO buytbl VALUES(NULL, 'SSK', '책' , '서적', 15, 5);
INSERT INTO buytbl VALUES(NULL, 'EJW', '책' , '서적', 15, 2);
INSERT INTO buytbl VALUES(NULL, 'EJW', '청바지', '의류', 50, 1);
INSERT INTO buytbl VALUES(NULL, 'BBK', '운동화', NULL , 30, 2);
INSERT INTO buytbl VALUES(NULL, 'EJW', '책' , '서적', 15, 1);
INSERT INTO buytbl VALUES(NULL, 'BBK', '운동화', NULL , 30, 2);
위 데이터를 활용하여 여러 개의 프로시저를 작성해볼 수 있었다.
USE sqldb;
DROP PROCEDURE IF EXISTS userProc;
CREATE PROCEDURE userProc(
IN userBirth INT,
IN userHeight INT
)
BEGIN
SELECT * FROM userTbl
WHERE birthYear > userBirth AND height > userHeight;
END ;
CALL userProc(1970, 178);

위 프로시저는 두 개의 INT 값을 매개변수로 받아서, 해당 값들을 이용하여 userTbl 에 있는 데이터들을 조회하는데 사용한다. 그 다음으로는 CASE, WHEN, THEN 문을 사용한 프로시저를 작성해보았다.
CREATE PROCEDURE caseProc(
IN userName VARCHAR(10)
)
BEGIN
DECLARE bYear INT;
DECLARE tti CHAR(3);
SELECT birthYear INTO bYear FROM usertbl u
WHERE name = userName;
CASE
WHEN (bYear % 12 = 0) THEN SET tti = '원숭이';
WHEN (bYear % 12 = 1) THEN SET tti = '닭';
WHEN (bYear % 12 = 2) THEN SET tti = '개';
WHEN (bYear % 12 = 3) THEN SET tti = '돼지';
WHEN (bYear % 12 = 4) THEN SET tti = '쥐';
WHEN (bYear % 12 = 5) THEN SET tti = '소';
WHEN (bYear % 12 = 6) THEN SET tti = '호랑이';
WHEN (bYear % 12 = 7) THEN SET tti = '토끼';
WHEN (bYear % 12 = 8) THEN SET tti = '용';
WHEN (bYear % 12 = 9) THEN SET tti = '뱀';
WHEN (bYear % 12 = 10) THEN SET tti = '말';
ELSE SET tti = '양';
END CASE;
SELECT CONCAT(userName, '의 띠 = ', tti);
END ;
CALL caseProc('성시경');

위와 같은 것 외에도, while 문도 아래와 같이 프로시저 내에서 활용해볼 수 있다.
DROP TABLE IF EXISTS guguTbl;
CREATE TABLE guguTbl (txt VARCHAR(100));
DROP PROCEDURE IF EXISTS whileProc;
CREATE PROCEDURE whileProc()
BEGIN
DECLARE str VARCHAR(100);
DECLARE i INT;
DECLARE k INT;
SET i = 2;
WHILE (i < 10) DO
SET str = '';
SET k = 1;
WHILE (k < 10) DO
SET str = CONCAT(str, ' ', i, 'x', k, '=', i*k);
SET k = k + 1;
END WHILE;
SET i = i + 1;
INSERT INTO guguTbl VALUES (str);
END WHILE;
END
CALL whileProc();
SELECT * FROM guguTbl;

이렇게 생성한 프로시저의 정보를 확인해야할 때도 있을 것이다. 이는 INFORMATION_SCHEMA 데이터베이스의 ROUTINES 테이블과 PARAMETERS 테이블을 조회하면된다.
SELECT routine_name, routine_definition from information_schema.routines where routine_schema = 'sqldb' AND routine_type = 'PROCEDURE';
SELECT parameter_mode, parameter_name, dtd_identifier, specific_name from information_schema.parameters WHERE specific_name = 'userProc';


위 테이블을 조회하는 것외에도, SHOW CREATE PROCEDURE 문으로도 Stored Procedure 의 내용을 확인할 수 있다.
SHOW CREATE PROCEDURE sqldb.whileProc

Stored Procedure 을 사용하는 것에는 몇 가지 강점이 있다. 첫 번째로, 이는 MySQL 의 성능을 향상시킬 수 있다. 긴 코드로 구현된 쿼리를 실행하면 클라이언트에서 서버로 쿼리의 모든 텍스트가 전송되어야 하는 반면, 이를 Stored Procedure 로 저장해두었다면 훨씬 적은 글자를 보내면 되기 때문에 네트워크의 부하를 줄일 수 있다. 두 번째로 유지관리가 편해진다. 클라이언트 응용 프로그램에서 직접 SQL 문을 짜지 않고 Stored Procedure 을 호출하게 함으로써 데이터베이스에서 관련된 내용을 일관되게 수정/유지보수 작업을 할 수 있다. 세 번째로는, 모듈식 프로그래밍이 가능해진다. 마지막으로, 보안을 강화할 수 있다. 사용자별로 테이블에 접근 권한을 주지 않고, 스토어드 프로시저에만 접근 권한을 줌으로써 좀 더 보안을 강화할 수 있는 것이다.
MySQL 에서는 Stored Procedure 뿐만 아니라, Stored Function 도 제공한다. 이는 스토어드 프로시저와 상당히 유사하지만, 형태와 사용 용도에는 약간의 차이가 있다고 한다. 아래는 하나의 예시 코드다.
DROP FUNCTION IF EXISTS getAgeFunc;
CREATE FUNCTION getAgeFunc(bYear INT)
RETURNS INT
NO SQL
BEGIN
DECLARE age INT;
SET age = YEAR(CURDATE()) - bYear;
RETURN age;
END ;
SELECT getAgeFunc(1999);

Stored Function 은 Stored Procedure 과는 다르게 IN, OUT 을 사용할 수 없다. 스토어드 함수의 파라미터는 모두 입력 파라미터로만 사용된다. 또, 스토어드 함수는 RETURNS 문으로 반환할 값의 데이터 형식을 지정하고, 본문 안에서는 RETURN 문으로 하나의 값을 반환해야 한다. (스토어드 프로시저는 별도의 반환하는 구문이 없으며, 필요하다면 여러 개의 OUT 파라미터를 사용해서 값을 반환할 수 있다) 스토어드 프로시저와 다르게 SELECT 로 호출된다는 점과, 스토어드 함수 안에서는 집합 결과를 반환하는 SELECT 를 사용할 수 없다는 점이 차이점이다.
마지막으로, Cursor 라는 것에 대해서도 알아보았다. 커서는 일반 프로그래밍 언어의 파일 처리와 방법이 비슷하다. 커서는 테이블에서 여러 개의 행을 쿼리한 후, 쿼리의 결과인 행 집합을 한 행씩 처리하기 위한 방법이다. 예를 들어, 파이썬에서 파일을 읽을 때 파일을 연 후, 한 행씩 읽게된다. 한 행씩 읽을 때마다 파일 포인터는 다음 줄을 가리키게 된다. 커서도 이와 비슷한 것이다. 아래와 같은 커서를 활용한 스토어드 프로시저를 작성해볼 수 있다.
USE sqldb;
DROP PROCEDURE IF EXISTS cursorProc;
CREATE PROCEDURE cursorProc()
BEGIN
DECLARE userHeight INT;
DECLARE cnt INT DEFAULT 0;
DECLARE totalHeight INT DEFAULT 0;
DECLARE endOfRow BOOLEAN DEFAULT FALSE;
DECLARE userCursor CURSOR FOR
SELECT height FROM userTbl;
DECLARE CONTINUE HANDLER
FOR NOT FOUND SET endOfRow = TRUE;
OPEN userCursor;
cursor_loop: LOOP
FETCH userCursor INTO userHeight;
IF endOfRow THEN
LEAVE cursor_loop;
END IF;
SET cnt = cnt + 1;
SET totalHeight = totalHeight + userHeight;
END LOOP cursor_loop;
SELECT CONCAT('고객 키의 평균 = ',(totalHeight/cnt));
CLOSE userCursor;
END
CALL cursorProc();

위 예는 AVG() 함수와 동일한 역할을 한다. 물론 위처럼 함수를 만들어 사용하는 것보다 AVG() 내장함수를 사용하는 것이 효율적이지만, 위와 같은 코드를 통해 조건을 걸어주거나 커스터마이징이 가능한 것이다.
ALTER TABLE userTbl ADD grade VARCHAR(5);
DROP PROCEDURE IF EXISTS gradeProc;
CREATE PROCEDURE gradeProc()
BEGIN
DECLARE id VARCHAR(10);
DECLARE hap INT;
DECLARE userGrade CHAR(5);
DECLARE endOfRow BOOLEAN DEFAULT FALSE;
DECLARE userCursor CURSOR FOR
SELECT U.userid, sum(price*amount)
FROM buyTbl B
RIGHT OUTER JOIN userTbl U
ON B.userid = U.userid
GROUP BY U.userid, U.name;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET endOfRow = TRUE;
OPEN userCursor;
grade_loop: LOOP
FETCH userCursor INTO id, hap;
IF endOfRow THEN LEAVE grade_loop; END IF;
CASE
WHEN (hap >= 1500) THEN SET userGrade = '최우수고객';
WHEN (hap >= 1000) THEN SET userGrade = '우수고객';
WHEN (hap >= 1) THEN SET userGrade = '일반고객';
ELSE SET userGrade = '유령고객';
END CASE;
UPDATE userTbl SET grade = userGrade WHERE userID = id;
END LOOP grade_loop;
CLOSE userCursor;
END;
CALL gradeProc();
SELECT * FROM usertbl u ;
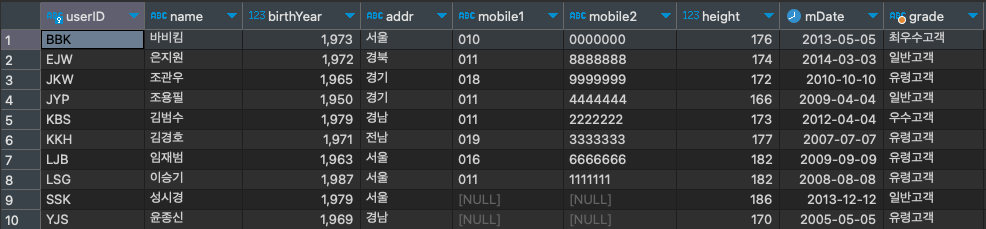
위와 같이 기존데이터를 활용하여 추가데이터를 작성할 때에도 커서가 유용하게 사용될 수 있을 것이다.
Reference:
이것이 MySQL 이다
'DB > MySQL' 카테고리의 다른 글
| MySQL 6: 전체텍스트 검색 & 파티션 (0) | 2023.06.23 |
|---|---|
| MySQL 5: Index (0) | 2023.06.21 |
| MySQL 4: Trigger, Event Scheduler (0) | 2023.06.19 |
| MySQL 2: SQL (0) | 2023.06.17 |
| MySQL 1: SQL (1) | 2023.06.14 |



