
elevne's Study Note
NLP 공부 (1: Vectorizer, 형태소분석기, re) 본문
각종 자연어처리 기법을 사용하기 위해서는 자연어데이터를 숫자데이터로 변환하는 과정이 필요하다. Scikit-Learn 라이브러리를 활용하여 이를 간단하게 진행할 수 있는 방법 2가지에 대해 알아보았다.
1. CountVectorizer
CountVectorizer은 자연어 데이터에서 단어의 빈도수에 따라서 특징을 추출하는 방식이다. 아래와 같은 코드로 쉽게 사용해볼 수 있다.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
data = ["자연어처리 공부 하는 중", "오늘 저녁에 약속이 있다", "약속에 나가서 친구와 같이 공부를 하기로 했다"]
vectorizer.fit(data)
vectorizer.transform([data[0]]).toarray()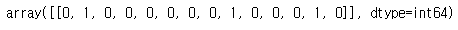
손쉽게 자연어 데이터의 특징 추출이 가능하긴 하지만 불필요한 단어의 영향(불용어 등)이 크다는 단점이 있다. 이러한 문제점을 보완할 수 있는 방식으로, TF-IDF 방식이 있다.
2. TF-IDF
TF(Term Frequency)는 문서 빈도 값으로 특정 단어가 여러 데이터에 자주 등장하는지를 알려주는 지표이며, IDF(Inversed Document Frequecy)는 특정 단어가 여러 데이터에 자주 등장할 수록 중요도를 낮게 평가하는 지표이다. TF-IDF는 이 두 값을 곱해서 단어가 어떠한 특정 문서에서는 많이 등장하지만, 다른 문서에서는 많이 등장하지 않는 것일수록 높은 값이 나오게끔 설계되어 있다.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
data = ["자연어처리 공부 하는 중", "오늘 저녁에 약속이 있다", "약속에 나가서 친구와 같이 공부를 하기로 했다"]
vectorizer.fit(data)
print(vectorizer.vocabulary_)
print(vectorizer.transform([data[0]]).toarray())
또, 자연어처리를 효과적으로 진행하기 위해서는 Vectorizer를 사용하기 전, 많은 전처리 단계를 거쳐야 할 것이다.
한글 자연어처리 라이브러리인 KoNLPy를 사용하여 형태소 분석을 진행할 수 있을 것이다. (한글 자연어 데이터의 경우에는 영어와 다르게 띄어쓰기만으로 효과적으로 텍스트를 분리하기가 어렵기 때문에, 형태소 단위로 토크나이징이 필요한 경우가 많을 것이다.) KoNLPy에는 Hannanum, Kkma, Komoran, Mecab, Okt 5개의 형태소 분석기가 포함되어 있다. 그 중 하나의 예시로 Okt의 함수에 대해 살펴보자면
from konlpy.tag import Okt
okt = Okt()
data = "나는 오늘 자연어처리 공부를 하는 중이다 ㅎㅎ"
print("Okt.morphs =>", okt.morphs(data))
print("Okt.morphs(stemp=True) =>", okt.morphs(data, stem=True)) #형태소단위로 나누기
print("Okt.morphs(norm=True) =>", okt.morphs(data, norm=True)) #정규화
print("Okt.nouns(data) =>",okt.nouns(data)) #명사만 출력
print("Okt.phrases(data) =>", okt.phrases(data)) #어절 출력
print("Okt.pos(data, join=True) =>", okt.pos(data, join=True)) #형태소와 품사
Okt 외의 다른 형태소 분석기들도 대동소이한 함수/기능을 지니고 있는 것으로 알고있다.
또, 전처리를 위해서 re 라이브러리를 사용하게될 것이다. re는 Regular Expression(정규표현식)의 약자로 파이썬 내장 라이브러리이다.
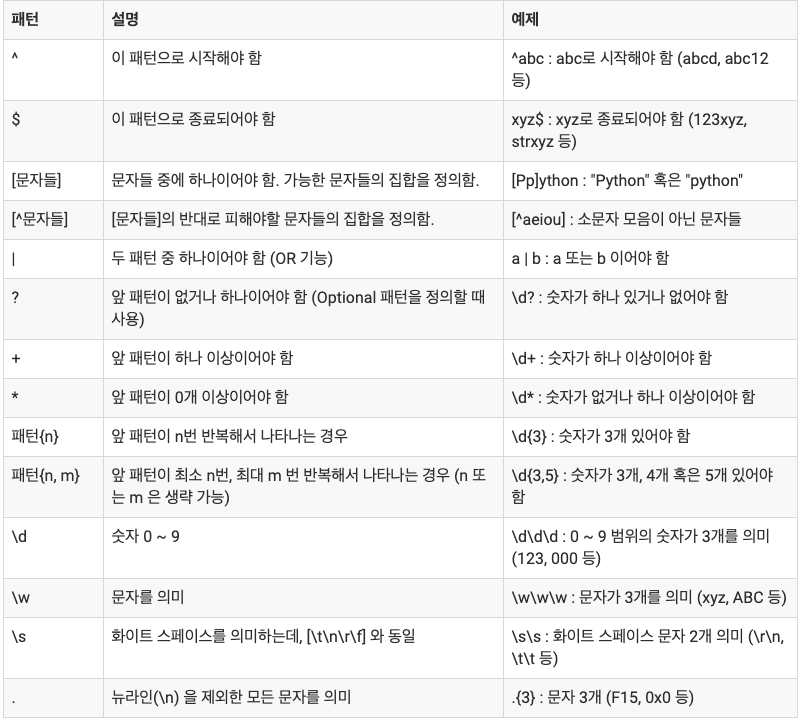
re의 몇 가지 함수에 대해 알아보자면
import re
data = "나는 오늘 자연어처리 공부를 하는 중이다"
pattern = "\w\s|\s\s"
re_pattern = re.compile(pattern) #compile해둔 패턴을 필요할 때 쉽게 재사용 가능
print("re.search", re.search("\w\w\w", data)) #패턴에 해당하는 첫 부분을 찾는 함수
print("re.split",re.split("\s", data)) #패턴을 기준으로 문자열을 나누는 함수
print("re.sub", re.sub("\s", "공백", data)) #패턴에 해당하는 곳을 두 번째 매개변수로 대체하는 함수
자주 사용하는 정규식표현 몇 가지를 찾아서 공부해보았다.
이메일
/^[a-z0-9_+.-]+@([a-z0-9-]+\.)+[a-z0-9]{2,4}$/
HTML 태그
/\<(/?[^\>]+)\>/
전화 번호 - 예, 123-123-2344 혹은 123-1234-1234:
/(\d{3}).*(\d{3}).*(\d{4})/
적어도 소문자 하나, 대문자 하나, 숫자 하나가 포함되어 있는 문자열(8글자 이상 15글자 이하) - 올바른 암호 형식을 확인할 때 사용될 수 있음:
/(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,15}/
숫자만 가능 : [0 ~ 9 ] 주의 : 띄어쓰기 불가능
/^[0-9]+$/
숫자만 가능 : [ 0 ~ 9 ] 주의 : 띄어쓰기 불가능
/^[0-9]+$/
이메일 형식
/^([\w-]+(?:\.[\w-]+)*)@((?:[\w-]+\.)*\w[\w-]{0,66})\.([a-z]{2,6}(?:\.[a-z]{2})?)$/
한글만 가능 : [ 가나다라 ... ] 주의 : ㄱㄴㄷ... 형식으로는 입력 불가능 , 띄어쓰기 불가능
/^[가-힣]+$/
한글,띄어쓰기만 가능 : [ 가나다라 ... ] 주의 : ㄱㄴㄷ... 형식으로는 입력 불가능 , 띄어쓰기 가능
/^[가-힣\s]+$/
영문만 가능 :
/^[a-zA-Z]+$/
영문,띄어쓰기만 가능
/^[a-zA-Z\s]+$/
전화번호 형태 : 전화번호 형태 000-0000-0000 만 받는다. ]
/^[0-9]{2,3}-[0-9]{3,4}-[0-9]{4}$/
도메인 형태, http:// https:// 포함안해도 되고 해도 되고
/^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/
도메인 형태, http:// https:// 꼭 포함
/^((http(s?))\:\/\/)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/
도메인 형태, http:// https:// 포함하면 안됨
/^[^((http(s?))\:\/\/)]([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/
한글과 영문만 가능
/^[가-힣a-zA-Z]+$/;
숫자,알파벳만 가능
/^[a-zA-Z0-9]+$/;
주민번호, -까지 포함된 문자열로 검색
/^(?:[0-9]{2}(?:0[1-9]|1[0-2])(?:0[1-9]|[1,2][0-9]|3[0,1]))-[1-4][0-9]{6}$/
출처:
https://velog.io/@ash3767/python-%EC%A0%95%EA%B7%9C%EC%8B%9D
'Machine Learning > NLP' 카테고리의 다른 글
| NLP 공부 (5-1: Transformer) (0) | 2022.10.23 |
|---|---|
| NLP 공부 (4-2: Seq2Seq with Attention) (0) | 2022.10.22 |
| NLP 공부 (4-1: Seq2Seq with Attention) (0) | 2022.10.21 |
| NLP 공부 (3: 감성분석) (1) | 2022.10.18 |
| NLP 공부 (2: Embedding(Word2Vec)) (0) | 2022.10.16 |



