
elevne's Study Note
딥러닝 파이토치 교과서 (6-6: 이미지분할을 위한 신경망) 본문
Image Segmentation (이미지 분할) 은 신경망을 훈련시켜 이미지를 픽셀 단위로 분할하는 것이다. Image Segmentation 의 대표적인 예로 Fully Convolutional Network, Convolutional & Deconvolutional Network, U-Net, PSPNet, DeepLabv3/DeepLabv3+ 등이 있다.
Fully Convolutional Network
완전연결층의 한계는 고정된 크기의 입력만 받아들이며, 완전연결층을 거친 후에는 위치 정보가 사라진다는 것이다. 이러한 문제를 해결하기 위해 완전연결층을 1 x 1 합성곱으로 대체하는 것이 Fully Convolutional Network 이다. 이는 CNN 기반 모델들을 변형시켜 이미지 분할에 적합하도록 만든 네트워크이다. 아래와 같이 AlexNet 에 사용된 Fully Connected Layer 을 Fully Convolutional 로 변경해주면 위치 정보가 남아있게 되어 고양이의 위치를 확인할 수 있다.

Convolutional & Deconvolutional Network
FCN 은 위치 정보가 보존된다는 장점이 있지만, 여러 단계의 합성곱층과 풀링층을 거치면서 해상도가 낮아진다는 점과 낮아진 해상도를 복원하기 위해 업 샘플링 방식(최종 이미지의 크기가 입력 이미지의 크기와 같도록 하는 것)을 사용하기에 이미지의 세부 정보들을 잃어버린다는 단점들이 있다. Convolutional & Deconvolutional Network 은 이러한 문제점들을 해결한다.

Deconvolutional Layer 은 CNN 의 최종 출력 결과를 입력 이미지의 크기와 같은 크기로 만들고 싶을 때 사용한다. Semantic Segmentation 등에 활용하며, 이를 Upsampling 이라고도 부르는 것이다. Deconvolutional Layer 은 기존 Convolutional Layer 과 다르게 특성 맵 크기를 줄이는게 아니라 증가시킨다. 우선 각각의 픽셀 주위에 Zero-Padding 을 추가하고, 패딩된 것에 합성곱 연산을 수행하는 방식으로 진행된다.
U-Net
U-Net 은 바이오 메디컬 이미지 분할을 위한 합성곱 신경망이다. 이는 속도가 빠르며 Trade-off 에 빠지지 않는다는 특징이 있다. 기존 Sliding window 방식은 이전 Patch 에서 검증이 끝난 부분을 다음 패치에서 또 검증하기 때문에 속도가 느렸지만, U-Net 은 검증이 끝난 패치는 건너뛰어 속도가 빠르다. 일반적으로 패치 크기가 커진다면 넓은 범위의 이미지를 인식하는데 뛰어나기에 Context 인식에 탁월하지만, 지역화에 한계를 갖게된다. 하지만 U-Net 은 이러한 Context 인식과 지역화의 Trade-off 문제를 개선하였다.
이러한 U-Net 은 FCN 을 기반으로 구축되었으며, Contracting Path 와 Expansive Path 로 구성되어 있다. Contracting Path 는 Context 를 포착하고 Expansive Path 는 Feature map 을 Upsampling 하고 Contractive Path 에서 포착한 Feature map 의 Context 와 결합하여 정확한 지역화를 수행한다고 한다. 아래 이미지와 같은 구조로 이루어진다.

PSPNet
Pyramid Scene Parsing Network, PSPNet 또한 Fully Connected Layer 의 한계를 극복하기 위해 피라미드 풀링 모듈을 추가하였다. 이는 우선 이미지 출력이 서로 다른 크기가 되도록 여러 차례 풀링을 진행한다. 1 x 1, 2 x 2, 3 x 3, 6 x 6 크기로 풀링을 수행하며, 이 때 1 x 1 크기의 특성 맵이 가장 광범위한 정보를 담게 된다. 각각 다른 크기의 특성 맵은 서로 다른 영역들의 정보를 담게되는 것이다. 이후 1 x 1 합성곱을 사용하여 채널 수를 조정한다. 그 다음으로는 입력 크기에 맞게 Feature map 을 Upsampling 하는데 이 과정에서 Bilinear Interpolation 기법이 사용된다. 마지막으로 이전 과정에서 생성한 새로운 Featuer map 들을 병합하는 것이다.

DeepLabv3/DeepLabv3+
DeepLabv3/DeepLabv3+ 또한 FCL 의 단점을 보완하기 위해 Atrous 합성곱을 사용한다. Encoder, Decoder 구조를 가지고, 일반적으로 Encoder-Decoder 구조에서 불가능하였던 Encoder 에서 추출된 Featuer map 의 해상도를 Atrous 합성곱을 도입하여 제어할 수 있도록 하였다.
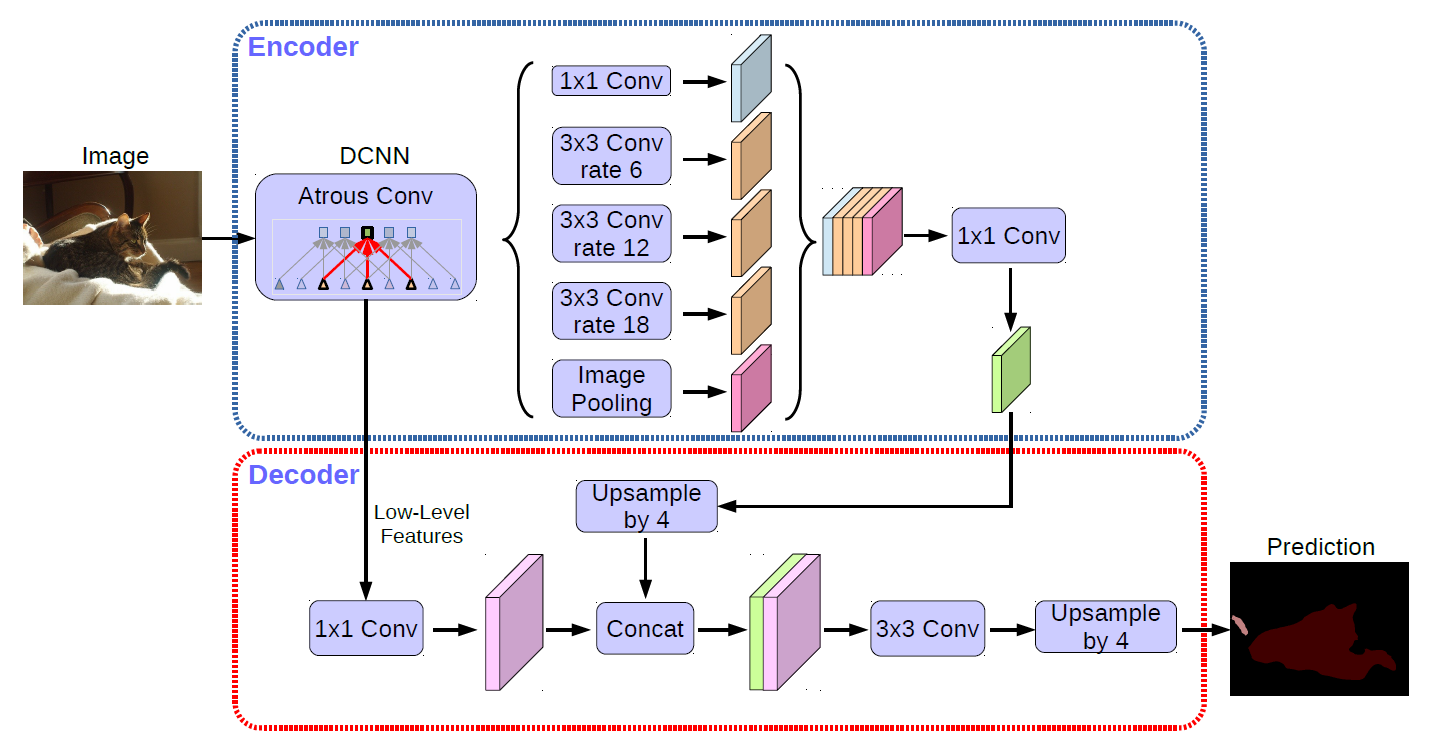
Atrous 합성곱은 위와 같이 필터 내부에 빈 공간을 둔 채로 작동하게된다. 여기서, 얼마나 많은 빈 공간을 가질지 결정하는 rate 파라미터를 사용한다. rate = 1 일 경우 기존 합성곱과 동일하게 빈 공간을 가지면, 이 값이 커질수록 빈 공간은 더욱 많아진다. 이러한 방식은 동일한 Computational Cost 로 더 넓은 Receptive Field (수용영역) 을 갖게해준다.
Reference:
딥러닝 파이토치 교과서

'Machine Learning > Pytorch' 카테고리의 다른 글
| 딥러닝 파이토치 교과서 (7-1: ~ARIMA) (0) | 2023.04.06 |
|---|---|
| 딥러닝 파이토치 교과서 (6-5: 객체인식을 위한 신경망) (0) | 2023.03.29 |
| 딥러닝 파이토치 교과서 (6-4: ResNet(2)) (0) | 2023.03.28 |
| 딥러닝 파이토치 교과서 (6-4: GoogLeNet, ResNet(1)) (0) | 2023.03.22 |
| 딥러닝 파이토치 교과서 (6-3: VGGNet (2)) (0) | 2023.03.21 |



